Machine Learning Development: A Comprehensive Review of Booktest and Testing Tools

Last updated on May 17, 2024
Before we begin, we’d like to set the expectations for you dear readers. We’re tackling a complex yet crucial topic in machine learning and AI development. And our goal? To make this intricate subject easy to understand for everyone, whether you’re an expert in the field or just starting to get curious.
Here’s our promise: We’ll keep things as straightforward as possible. Think of this as a casual chat where we unravel the complexities of ML testing, making it digestible for everyone, regardless of their technical background.
In this article, we will dissect the unique challenges of testing machine learning-enabled software and introduce you to Booktest – a revolutionary tool that connects the agility of Jupyter Notebook with the traditional unit testing. It’s an innovative approach that’s changing the game in data science and AI development.
So, let’s start this journey together. Whether you’re a seasoned data scientist or just curious about the field, we’re here to make this topic as accessible and engaging as possible.
In This Article:
How to Improve the Data Science and LLM Development Process
People who have worked in data science recognize instantly the following scene: A clever data scientist 1) copies code from the Git-repo to a Jupyter notebook, 2) tests some changes and 3) copies the changes back to Git and pushes them toward the production. This is an event, that will raise any prudent software engineer’s eyebrows. You can almost hear him mumble. “Copy-pasting code to production. It cannot be happening.”
Yet it happens.
It happens — unfortunately, but it happens for three very good reasons, which help highlight the fundamental differences between data science and software development. Understanding these reasons helps also highlight why the data scientist is actually quite clever to follow this process, and how the current QA tools are failing the data scientists.
Right/Wrong Testing vs. Good/Bad Testing
The first reason for the disconnect between software engineering and data science lies in how quality is measured. In software engineering, quality is often about something working correctly or not. This can be seen as right/wrong testing, where tests yield clear positive or negative results. Most testing is based on simple assertions.
However, data science operates differently. Errors are expected, and the goal is to have fewer errors rather than none. Data science uses various metrics like precision, recall, rank, log likelihood, and information gain. These metrics don’t always align with each other or with user experience.
Often, results need to be reviewed visually in the user interface. Especially in unsupervised learning, useful metrics are rare. Therefore, data science results are evaluated on a good/bad scale, which often requires expert judgment.

Statistical, competing and subjective measurements and visuals create a completely different setting for quality assurance, when compared to traditional unit testing or regression testing. In such settings, the quality is impossible or impractical to test and regression test with purely algorithmic means.
This subjective nature of data science drives review-driven quality assurance. Experts need detailed information to decide if new results are better than old ones, identify imperfections, and guide further development.
While software engineers may rely on assertions and unit tests to verify system quality, they might find these methods slow and not very useful for ensuring quality in AI systems.
Unit tests don’t help in understanding the underlying system and its results. In contrast, data scientists use Jupyter Notebooks to create visualizations, metrics, and analyses to get a comprehensive view of results and the system.
By examining results, data scientists can identify issues like overfitting or missing features and make improvements. This better visibility reduces the number of iterations needed, increasing productivity. Clearly, this approach is more effective.
Iteration Speed and the Roman Census Approach
Understanding the iterative nature of development is key: you make changes, test them, and observe the results. Often, to create a solution, you need to repeat this cycle a hundred times. If each iteration takes 10 seconds, 100 iterations take about 15 minutes. But if each iteration takes 10 minutes, the full task stretches to 3 to 4 days, drastically reducing productivity.
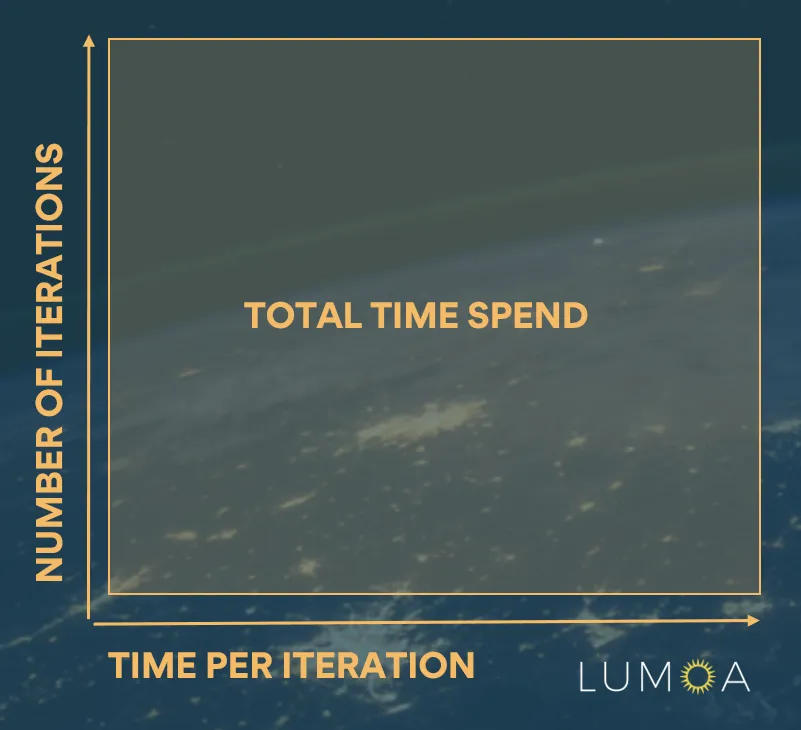
For an iterative task, the productivity is greatly determined by the number of iterations and the time per iteration. In data science, each iteration can take many magnitudes longer than in software engineering, because of much bigger data, much heavier processing, and bigger states.
Workflow significantly impacts productivity, and data scientists prefer Jupyter Notebooks for their faster iteration cycles. This preference is closely tied to the “Roman Census approach” central to Big Data. Instead of moving large data sets to the code, you move the code to the data, because big data is cumbersome to move.
When a data scientist prepares gigabytes of data or a large model, it might take seconds or minutes. Creating a model can take minutes, hours, or even days. On the other hand, a software engineer’s unit test setup might take milliseconds.
However loading gigabytes of data and creating an expensive model can make a single test take ten minutes, severely impacting iteration speed and productivity. The savvy data scientist uses Jupyter Notebooks to cache data and models in RAM, GPU, and disk.
This means that when code is modified, it can run in seconds using the already loaded and prepared data and models. This is the Roman Census approach in action: keeping the data warm and updating the code.
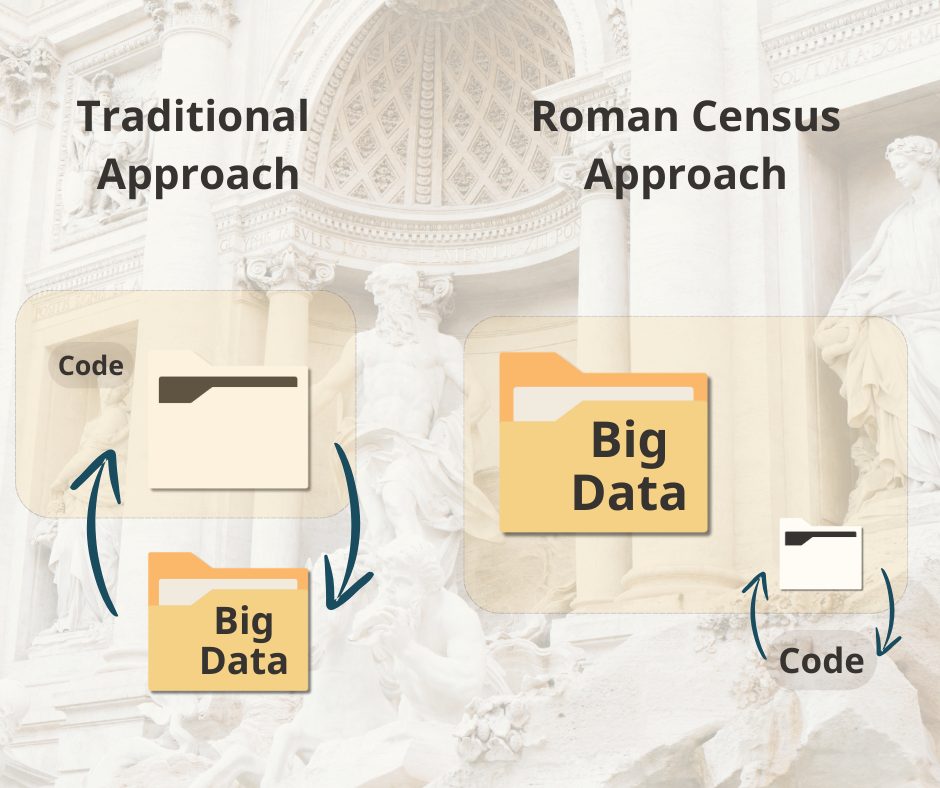
In the Roman census approach, the data is kept prepared and loaded, while the code is sent to where the data is. This makes operations faster in situations when transferring and reloading the code is faster than transferring and preparing the data.
Another productivity boost from Jupyter Notebooks is their ability to cache intermediate results, speeding up iteration on small pipeline parts. If a full 10-step pipeline takes 10 minutes to run, iterating on just one step might take only a minute. This 10x faster iteration leads to significantly higher productivity.
The number of iterations, diagnostics, and visibility of results
The third reason data scientists prefer Jupyter Notebooks is the enhanced visibility into results and system behavior they provide.
Jupyter Notebooks encourage users to print intermediate results and create visualizations throughout the development process. These outputs not only help monitor application quality but also highlight issues like overfitting or specific cases where the system lacks the necessary data to infer the correct result.
This better visibility into results and system behavior helps identify issues early and spot opportunities for improvement, such as introducing new data sources.
This improved visibility reduces the need for additional iterations to pinpoint root issues, allowing data scientists to achieve the desired quality in fewer iterations. Instead of needing 100 iterations to reach the necessary quality, a data scientist might only need 50.
Perfect for Purpose, Except That…
This approach sounds ideal and effective. The data scientist appears to be the hero, finding an efficient workflow. The review-driven approach to quality assurance, faster iteration cycles, and reduced iterations due to better system visibility lead to higher quality results and increased productivity.
Reduction in the number of iterations and time per iteration can drive a drastic decrease in the total time invested in a project.
Yet, there are some drawbacks. First, the data scientist still resorts to copy-pasting code between systems, introducing extra steps that consume time and can cause bugs.
Second, there’s no regression testing. If someone makes a change, the chances of system regression are high without retesting through this error-prone process. Additionally, the review process can be costly.
Do we need the data scientist to review the entire setup every time something changes?

Jupyter Notebook provides a superior process when developing data science solutions, but falls short, when productizing, maintaining, and regression testing the system.
Book test and review-driven testing
Introducing book test
Booktest is a review-based testing tool, that aims to combine the best sides of Jupyter Notebook with classic unit testing. Mainly, book test provides 3 main services
- Easy snapshotting and easy snapshot reviews and diffs to power review-driven development
- Internal build system providing RAM and FS caches
- Classic regression testing with easy CI integration
In more practical terms: Booktest could be characterized as a ‘diff tool’ that allows you to quickly run tests, use extensive caches, and see the result’s differences compared to the previous snapshot.
The example project
Booktest development is best described through an example. Let’s imagine a simple project containing a prediction engine called a predictor, which predicts whether an animal is a mammal based on its number of legs and wings and which provides an explanation for the inference. The predictor is stored in predictor/predictor.py and it looks like this:

To set up the booktest, you need first to create a directory for the tests. This directory can be named for example ‘book’ or ‘test’. In this example, we use the directory name ‘book’ to leave out the namespace for the traditional unit testing. In the book directory, we create a file called predictor_book.py’, which looks like the following:

In this test case, we assume the Predictor object to be ‘a big state’, which is expensive to create and load. For this reason, we return it as a test result and declare dependency with ‘depends_on’ decoration in the second test to that result. This allows caching the predictor in RAM and in FS for faster reuse when iterating the ‘test_predict_dog’ test case results.
The tln() method prints a message with a new line for review. The tool generates Markdown content, which may also contain headers, links, lists, tables, and images, and which can be viewed visually during review and also in Git.
Running booktest
Now that we have set up the test, we can run booktest in interactive (‘-i’ flag) and verbose (‘-v’ flag) mode:
 This will print the results of the first test case for review with a prompt about whether we are happy with the outcome.
This will print the results of the first test case for review with a prompt about whether we are happy with the outcome.

By typing ‘a’, we can accept the results. We can similarly review and accept the results from inference.

Now, if we make changes, we can rerun a specific test with:

If there are changes, then we can review the differences easily and re-accept them. A cache of the possibly expensive engine object is automatically loaded and used:

Once we are happy with the results, we can run book test in non-interactive mode locally or in CI like any regression test suite:

If a test case failed, the test run can be reviewed in interactive mode with ‘booktest -w –i’ or the failures can be printed (e.g. in CI) with ‘booktest -w –c –v’, where –c is used to only run/review the failed test cases.
As a summary, book test provides 1) review driven development flow, 2) powerful multi-level caching and 3) CI compatible regression testing.
Booktest in real-life use
The quality to assure
While simple examples are educational, the real benefits are best understood in the context of real data science projects. Here, I’m going to use Lumoa text analytics engine as a real-life example, of using booktest to develop a complex machine learning system and assure its quality.
Here, Lumoa provides text analytics services for numerous stakeholders like customer insights professionals and — also — for product teams. The goal of the system is to take the user from a mountain of textual data into a view to the data, that is sensible and comprehensible. Here’s an example of the result for banking mobile application data for the July-September range in 2018.
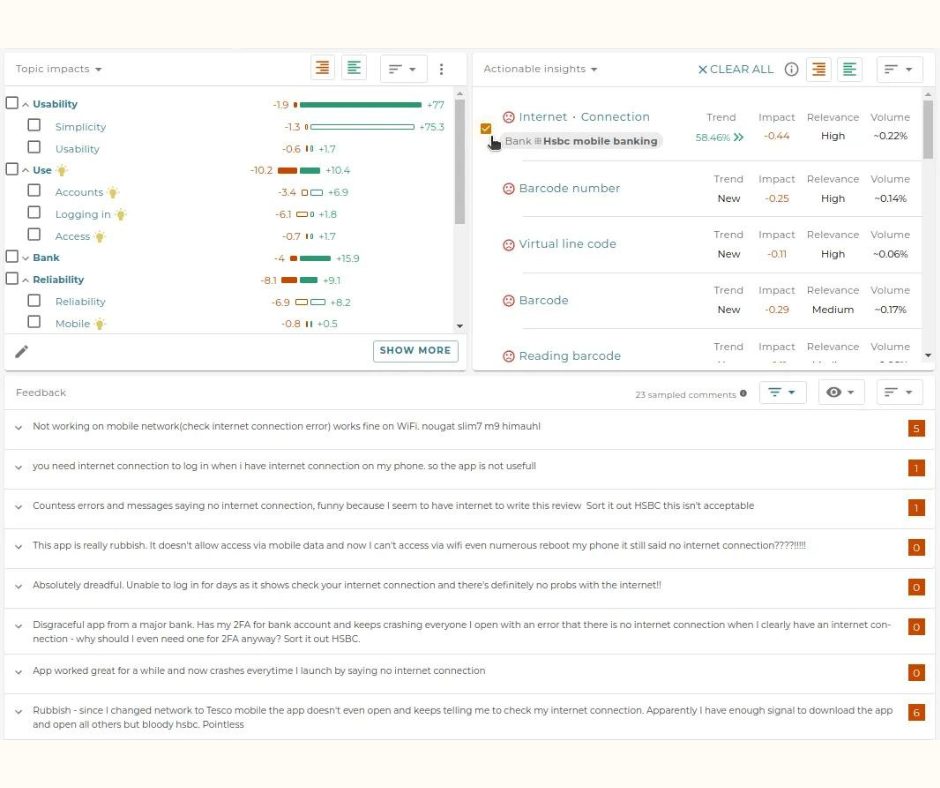
It demonstrates well 2 key aspects of the text analytics engine, that are the AI generated topic model on the left side with topics like Finance, Transactions and Identification. Another aspect is the ‘actionable insight’ view on the right with the top insight being the internet connection issues with HSBC mobile bank.
While the raw AI topic model itself looks superficially good, it does contain its flaws evident on deeper examination. Some of the topics have clearly AI generated names. Customer service subtopic is positioned under Quality and it contains not so useful ‘helpful’ keyword.
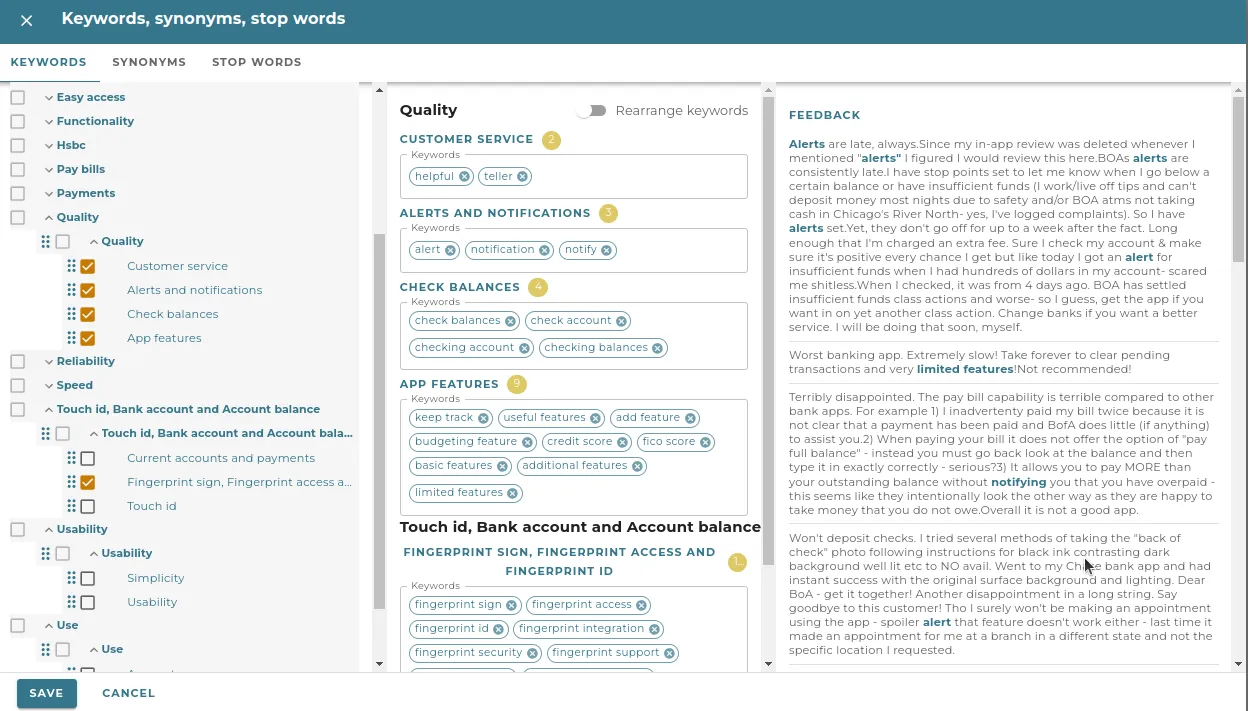
And truly, topic modelling is a hard problem. Lumoa’s experience is that the traditional textbook algorithms don’t really fit the purpose and — in practice — they don’t provide sufficient quality.
To deal with these challenges, we are employing a rather complex AI system, which includes LLM, knowledge base, supervised component, user preference modelling, and a statistical component based on a distributional hypothesis.
Also, to deal with AI’s mistakes: Lumoa has employed a ‘Hybrid AI’ approach, where the user can freely modify/curate the AI model, and AI can further build its changes/suggestions on top of manual changes.
With such a complex system, quality assurance plays an emphasized role.
Topic modelling and review driven testing
In Lumoa, the topic model quality is guaranteed by an extensive suite, which runs the topic model for about a dozen different data sets in a few dozen separate test settings. We have some metrics to measure the resulting topic model quality, yet the final quality assurance is done — you guessed it right — via an expert review.
The banking data test suite set itself contains 17 separate test cases:

In the test suite the ‘topics’ test run is used for creating topic modelling and reviewing results. As an experiment, we can recreate the impact of introducing the large language embeddings to topic modeling by first disabling it and then by enabling it again. When running book test it will fail, with the option to run a ‘diff tool’ for review:

Diff opens Meld for comparing topic tree before (left, without LLM) and after (right, with LLM) the change. The topic trees are similar to what is visible in the UI and give a feel about what the result will look like for the user:

In the review we can see the distinct effects of the LLM embeddings:
- It helps merge long phrases with similar semantics into coherent topics (e.g. fingerprint-related phrases in the Account Management / Login topic)
- It also helps to deal with typos and different ways of writing words (e.g. bofa and boa)
- Still, LLM similarity metrics are not always very precise, and its generated topic structure does not resemble one built by a CX expert. Here preference modelling typically does a better job, as it seeks to mimic the way actual users/experts organize and construct topic structures.
For example, AI shouldn’t create a separate topic for fingerprint, but instead keep it inside a larger login/authentication topic). The overall topic structure may have — in fact — become worse.
While LLM provides mixed results in this data set, it provides a much clearer improvement with smaller data sets, with rarer words, and with domains and languages, that are not well covered by our knowledge base or our user preference data.
These benefits are revealed by other test cases and also by evaluation tests, which measure accuracies and also information gain for the predicted merging probabilities based on a curated ground truth.
Review-driven testing for insights
Besides topic modelling, one of the key functionalities in Lumoa is called ‘insights’, which tests demonstrate the benefits of the review approach and the MD format. Here, we can see the actionable insights for the banking collection with a simple command:

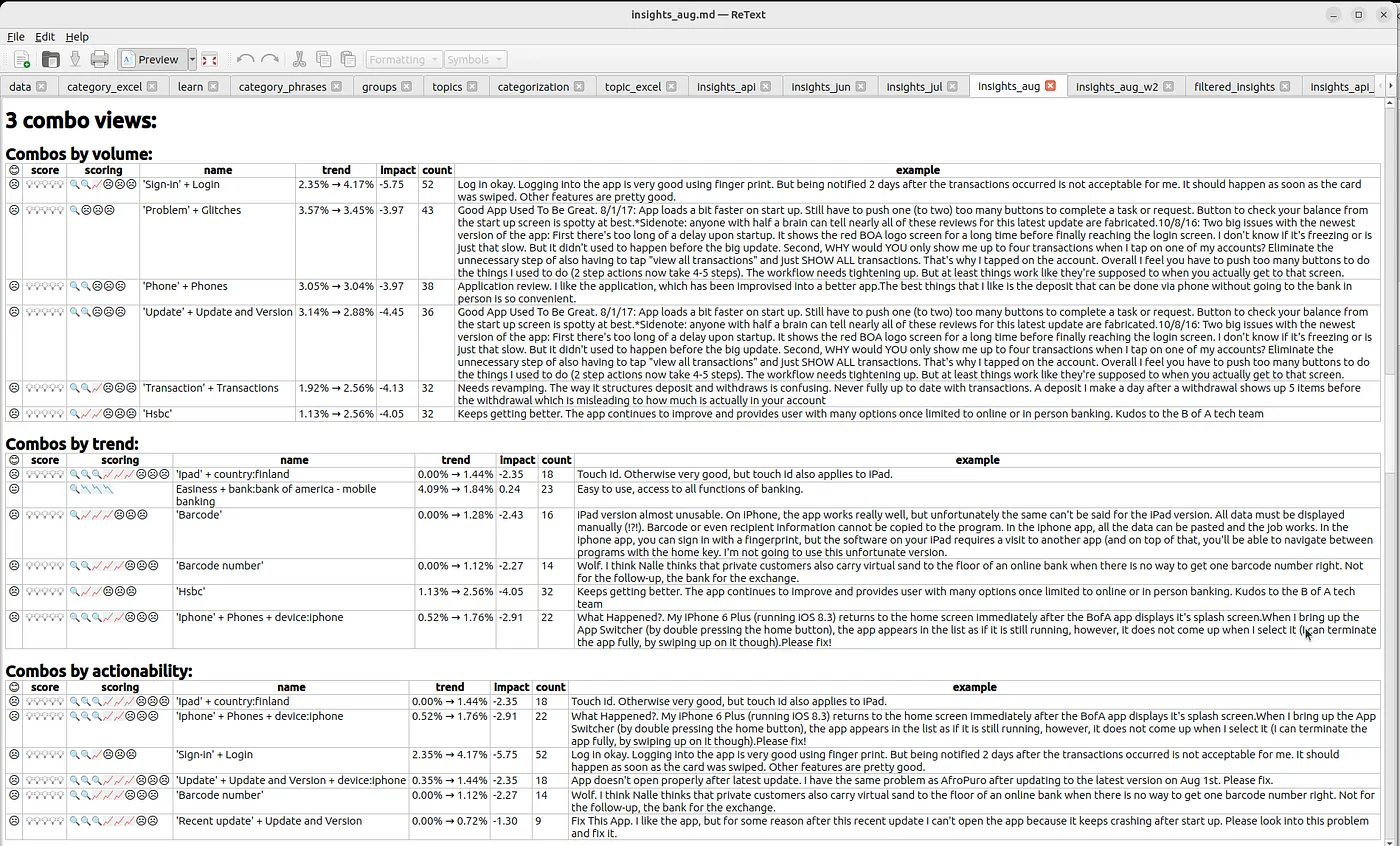
We are looking at one test case result, which shows insights for August 2018. The above results demonstrate how headers, tables, and visual icons can be used to display results and mimic the UI with booktest and Markdown
Now, because the data and date selection are similar to what we had in the previous UI screenshot, the results also look similar. In the ‘combos by actionability’ part, we can see the familiar ‘barcode’ issue with the Nordea mobile bank.
As an addition to the issue and its relevance score, we can also dig deeper into why the system thought the issue was ‘relevant/actionable’ and why it deserves a high score.
In the scoring field, you can see 3 sub-scores for the insight that are:
a) looking glass for the level of detail/concreteness,
b) uptrend icon for the trend
c) and unhappy faces for impact.
Looking at the row, we can see that the issue has a massive uptrend (from 0% -> 1.2%), it’s highly impactful, and it’s pretty concrete as its description contains both the problem (‘barcode’) and diagnostical information of its location (‘Nordea bank app’).
The overall test suite now contains 268 tests, which cover high-level results tests, measurement benches, tests for smaller components/units, and tests for various languages, scales, and contexts. The major part of the tests is run parallel with coverage measurement in the CI, though the heaviest testing is omitted to avoid too slow CI runs.
This testing approach has proven itself to be effective in supporting the data science development process and guaranteeing the system’s quality.
Conclusion
You’ve made it to the end—congratulations! As we’ve explored, data science results aren’t simply right or wrong; they exist on a spectrum of good and bad. This nuanced nature demands a unique approach to quality assurance. Through our journey, we’ve highlighted how integrating the agility of Jupyter Notebooks with the rigor of traditional unit testing fosters a review-driven testing methodology.
Booktest stands at the forefront of this innovative approach. Though it’s a relatively new and straightforward tool, it offers essential functionalities:
- Easy Snapshotting and Review: Markdown files, tools, and workflows tailored for continuous reviews, enabling clear and comprehensive documentation of results.
- Internal Build System: With dependency tracking and robust RAM+FS caches, it ensures efficient handling of large data sets and models.
- Regression Testing: Capable of parallelization and coverage measurements, it integrates seamlessly with continuous integration (CI) processes.
But don’t just take our word for it—experience the power of review-driven quality assurance firsthand. We invite you to try the Lumoa free trial and witness how Booktest can enhance your data science and AI development projects.
Thank you for sticking with us through this deep dive. Whether you’re a seasoned data scientist or a curious newcomer, we hope you’ve found this discussion insightful and engaging. Ready to revolutionize your workflow? See the difference for yourself! Try Lumoa Free
